

こんにちは、りょうです。本記事では独学コンピューターサイエンティストのアルゴリズム編の章末の演習問題を書籍に習って図解を用いながらわかりやすく解説していきます。
- Pythonの初学者
- アルゴリズムとデータ構造に興味のある方
- コンピューターサイエンスを学ばずに実装している方
再帰的アルゴリズム、探索アルゴリズム、ソートアルゴリズム、文字列アルゴリズムの演習問題を取り扱います。
今やエンジニア採用時にコーディング試験を行う企業も増え、アルゴリズムとデータ構造への理解はエンジニアとして働く上で必須とされてきています。
本記事を読むことで、アルゴリズムへの理解が増し、コーディングスキルの向上などに役立ていただければ幸いです。
ぜひ、ご自身のPCで手を動かしながら、動作確認してみてくださいね!
再帰的アルゴリズム
再帰的アルゴリズムは元々の問題を小さな問題に分割していき、自分自身を呼び出す関数で終了条件を満たすことで関数をよびだすのをやめます。
それでは再帰的アルゴリズムの問題を解きながら、理解を深めていきましょう!
チャレンジ問題 & コード全文
再帰的に1から10までの数字を出力しよう。
独学コンピューターサイエンティスト
チャレンジ問題の回答例は以下のようになります。
ループを使うような反復的アルゴリズムに見慣れている方は、関数の中で関数が呼び出されていることに違和感を感じるかもしれませんね。
def print_recursive(n):
if n == 0:
return
print(n)
n -= 1
print_recursive(n)図解
-1-1-1024x726.png)
以下が再帰の3原則です。
- 再帰的アルゴリズムは、終了条件を持つ
- 再帰的アルゴリズムは、毎回状態を変え、終了条件に近づく
- 再帰的アルゴリズムは、それ自身を再帰的に呼び出す
図解では10を入力値として受け取り、終了条件に近づきながら、再帰的に関数が呼び出されています。
解説
print_recursive(それぞれ出力、再帰の意味)という関数を1行目で定義し、nを入力値として受け入れます。
def print_recursive(n):次に終了条件があり、nが0になるまでそれ自身を呼び出し続けます。nが0になったとき、Noneを戻り値として返し、関数の呼び出しを終了します。
Pythonではreturnのあとに何もコードがない場合はNoneを返します。
if n == 0:
return終了条件に当てはまらないときは、以下のコードを実行します。入力値として受け入れたnを出力し、nから1を引きます。
print(n)
n -= 1最後にn-1を入力値として自身を呼び出し、再帰を繰り返すと最終的にnが0になり、再帰が止まる仕組みです。
print_recursive(n)探索アルゴリズム
探索アルゴリズムはプログラマーが知っておくべきアルゴリズムの基礎知識という位置づけで、ほとんどのプログラマーはデータを扱い、多くのデータセットの中から目的のデータを探すことをしています。
線形探索、二分探索などの有名なアルゴリズムがあり、今回は二分探索アルゴリズムを用いた問題に取り組みます。
チャレンジ問題&コード全文
アルファベット順の単語のリストが与えられたとき、単語の二分探索を行い、単語がリストに含まれているかどうかを返す関数を書こう。
独学コンピューターサイエンティスト
def binary_search(a_list, c):
first = 0
last = len(a_list) - 1
target_code = ord(c)
while last >= first:
mid = (first + last)//2
if a_list[mid] == c:
return True
else:
if target_code > ord(a_list[mid]):
first = mid + 1
else:
last = mid - 1
return False図解
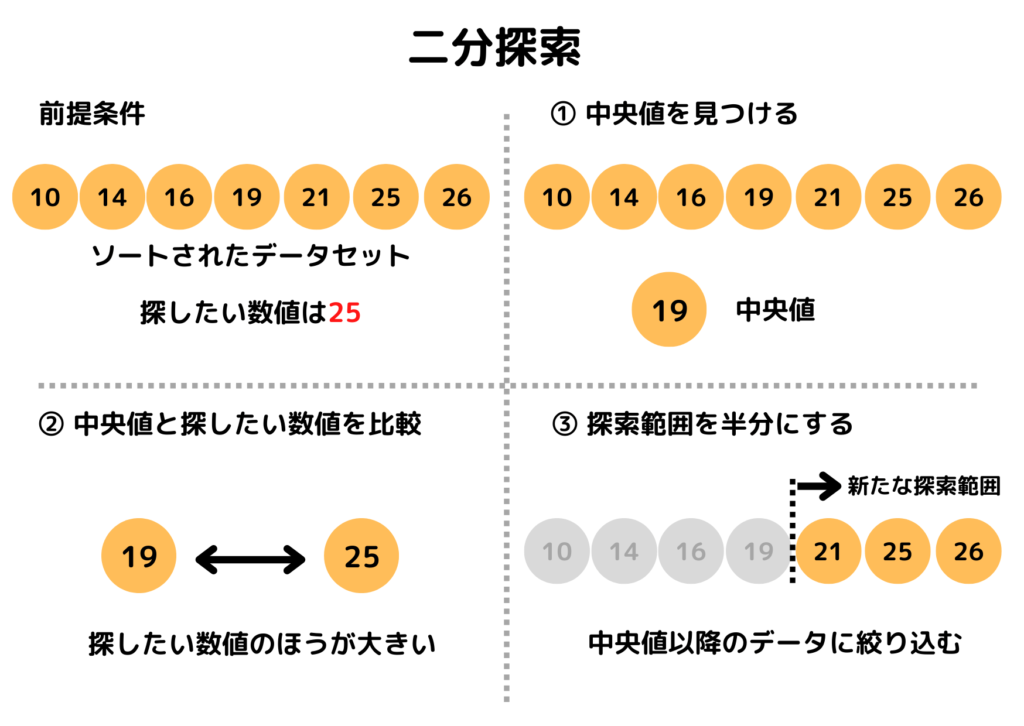
二分探索は主に3つの処理からなります。
- 真ん中の要素を選ぶ処理
- 真ん中のデータと目的のデータを比較する処理
- 探索の範囲を半分に狭める処理
コードを理解する前に図解でざっくりとしたイメージを掴んでいただけたらと思います。
解説
binary_searchを定義して、引数としてa_list(リスト型)、cに探索したい文字列を入力値として受け取ります。
def binary_search(a_list, c):firstに0、lastに引数として代入したリストの長さから1引いた値を格納します。
Pythonのリストのインデックスは0から始まるため、ここではリストの長さから1引いた値を格納しています。
first = 0
last = len(a_list) - 1探索したい文字列cをunicode値に変換します。
target_code = ord(c)whileループでlastがfirst以下の間はループを繰り返します。
while last >= first:midに中間のインデックスを格納します。
mid = (first + last)//2 # 例 mid = 5 (mid = 11 // 2)リストの真ん中の文字列と探索文字列を比較し、一致する場合はTrueを返します。
if a_list[mid] == c:
return True一致しない場合は探索文字列のUnicode値とリストの真ん中のUnicode値の大小を比較します。
探索文字列が大きい場合、firstに現在のmid + 1の値を代入し、探索範囲を絞り込みます。
if target_code > ord(a_list[mid]):
first = mid + 1探索文字列のUnicode値が小さい場合、lastに現在のmid – 1の値を代入し、探索範囲を絞り、再度whileループ内の処理を行います。
else:
last = mid - 1上記のどのパターンにも当てはまらなければ、不一致となりFalseを返します。
return Falseソートアルゴリズム
ソートアルゴリズムには下記のようなアルゴリズムがあります。
- マージソート
- クイックソート
- 挿入ソート
- バブルソート
- ヒープソート
- シェルソート
今回はその中のクイックソートについて解説していきたいと思います。
チャレンジ問題&コード全文
ソートアルゴリズムを調べて、この章で学んだバブルソート、挿入ソート、マージソート以外のソートアルゴリズムを書こう。
独学コンピューターサイエンティスト
def quick_sort(arr, left, right):
i = left + 1
k = right
while i < k:
while arr[left] > arr[i] and i < right:
i += 1
while arr[left] <= arr[k] and k > left:
k -= 1
if i < k:
temp = arr[i]
arr[i] = arr[k]
arr[k] = temp
if arr[left] > arr[k]:
temp = arr[k]
arr[k] = arr[left]
arr[left] = temp
if left < k-1:
quick_sort(arr, left, k-1)
if k + 1 < right:
quick_sort(arr, k+1, right)
return arr図解
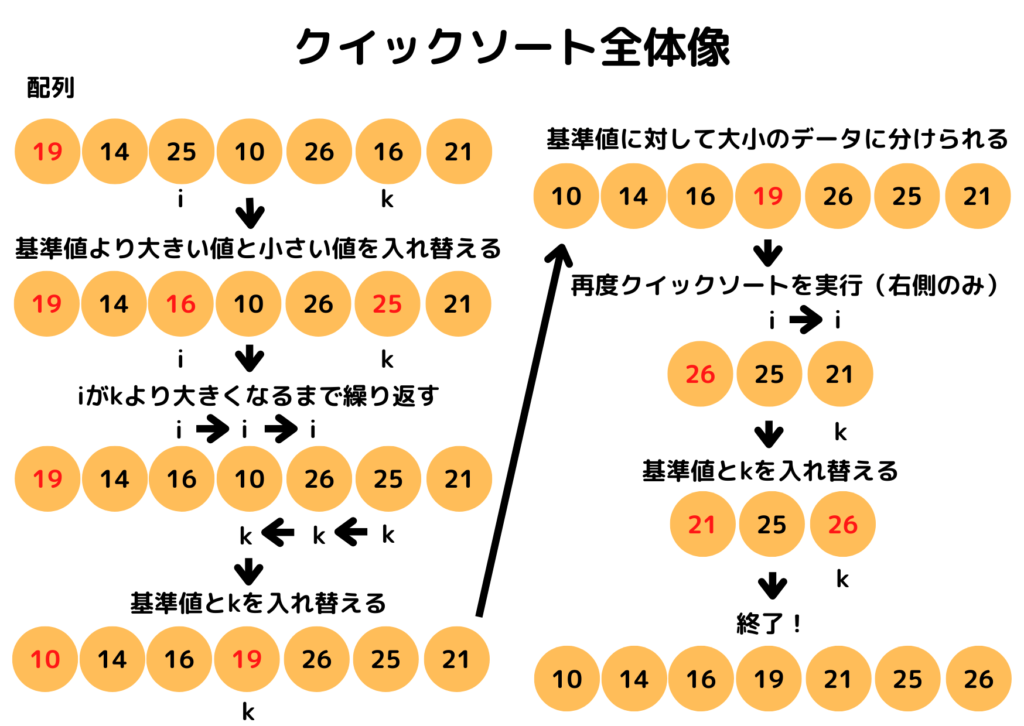
以下がクイックソートの主な処理です。
- 基準値を決めてデータを大小のグループ2つ二分割しながら全体を整列していく
- 配列の左と右から、それぞれ変数を動かして大小に並べ替えていく
- 上記2つの処理を繰り返し実装する
クイックソートの処理速度はO(log n)で、実行速度が速いのが特徴です。
解説
quick_sort関数を定義し、引数としてリストとリストの探索範囲の最初のインデックス(left)と最後のインデックス(right)を受け取ります。
def quick_sort(arr, left, right):基準値より大きいかを判定する変数であるi、基準値より小さいかを判定する変数であるkを用意します。
i = left + 1
k = rightiがkより小さい間は以下のループを行います。
while i < k:arr[i]を基準値(arr[left])と比較し、arr[i]が基準値より小さければ、iに1を加えていきます。
while arr[left] > arr[i] and i < right:
i += 1次にarr[k]が基準値より大きければ、kから1を引いていきます。
while arr[left] <= arr[k] and k > left:
k -= 1iとkのwhileループが終了したあと、基準値より大きいiの要素と基準値より小さいkの要素を入れ替えます。
if i < k:
temp = arr[i]
arr[i] = arr[k]
arr[k] = tempwhileループが終わったあとにarr[k]の要素と基準値を入れ替えます。そうすることで基準値より小さい要素が左側に、大きい要素が右側に並んだ配列が出来上がります。
if arr[left] > arr[k]:
temp = arr[k]
arr[k] = arr[left]
arr[left] = tempその後、上記のwhileループを再帰的アルゴリズムを用いて、基準値の左側の配列と右側の配列それぞれに行い、最後に配列(arr)を返します。
if left < k-1:
quick_sort(arr, left, k-1)
if k + 1 < right:
quick_sort(arr, k+1, right)
return arr文字列のアルゴリズム
文字列アルゴリズムはエンジニアの技術面接などでも問われやすいアルゴリズムです。アナグラムの見つけ方を学ぶことで、並べ替えのような概念を使って問題をとく力が身につきます。
以下が文字列アルゴリズムの代表例です。
- アナグラム検出
- 回文検出
- 最後の列の文字列検出
チャレンジ問題&コード全文
リスト内包表記を使って、以下のリスト内の単語のうち4文字以上の単語をリストとして返そう。
独学コンピューターサイエンティスト
a_list = ["selftaught", "code", "sit", "eat", "programming", "dinner",
"one", "two", "coding", "a", "tech"]
print([word for word in a_list if len(word) >= 4])解説
a_listにリストとして単語を格納します。
a_list = ["selftaught", "code", "sit", "eat", "programming", "dinner",
"one", "two", "coding", "a", "tech"]リスト内包表記ではforループでa_list内の単語を順次wordに格納し、wordの文字数が4文字以上であれば、printで出力する処理になっています。
print([word for word in a_list if len(word) >= 4])
# ['selftaught', 'code', 'programming', 'dinner', 'coding', 'tech']まとめ
本記事では独学コンピューターサイエンティスト【アルゴリズム編】の演習問題について、図解を交えながら1行ずつ解説しました。
アルゴリズムに精通することはエンジニアとして働く上で必須の知識です。ぜひ、ご自身のスキルアップに活かしてみてください。
次はデータ構造です。スタックやキューをはじめとした基本的な部分の章末問題を解説していきたいと思います。
最後まで読んでいただきありがとうございました。